
PnP-CoSMo: A Plug-and-Play Method for Guided Multi-contrast MRI Reconstruction based on Content/Style Modeling
What is the shared structural essence that underlies a pair of MRI contrast spaces? Explicitly capturing this contrast-invariant “content” leads to a powerful reconstruction algorithm.

The Inverse Problem of MRI Reconstruction
The reconstruction of an MR image from undersampled raw data is an ill-posed inverse problem — it has an infinite set of possible solutions, meaning that the forward model cannot be inverted to arrive at a unique image. A viable reconstruction process thus constitutes a synergetic interplay between two parts: (a) the physics of the measurement process, which is represented by the forward model, and (b) the a priori constraints we impose on the space of possible images based on our understanding of the problem beyond the forward model.
These constraints encode our prior knowledge about the underlying image before the measurement brings in the raw data, and they can take many forms. One of the most well-understood priors is the compressibility prior as used in compressed sensing (CS)[1]. CS resolves the ambiguity in the inversion problem by selecting the most compressible image (formulated as sparsity in a linear transform domain such as wavelet) from the full set of possible images consistent with the measured data.
Multi-Contrast Side Information
Sources of side information can inform our prior knowledge about the image to a greater extent than the compressibility criterion, thus serving as superior priors and enabling further undersampled acquisitions[2]. We are specifically interested in the guided multi-contrast reconstruction problem, where a reference scan that reflects the same underlying anatomy through a different contrast is available as side information. Denote the target contrast scan to be reconstructed as x*2, the raw k-space measurements of this scan as y, the forward model relating them as A, and the reference scan serving as the side information as xref1.
Naturally, the two scans also contain unique and complementary pieces of information, which is the reason both are acquired in a clinical MR exam. How shall we then encode this reference contrast scan as a prior in the problem of reconstructing the target contrast scan?
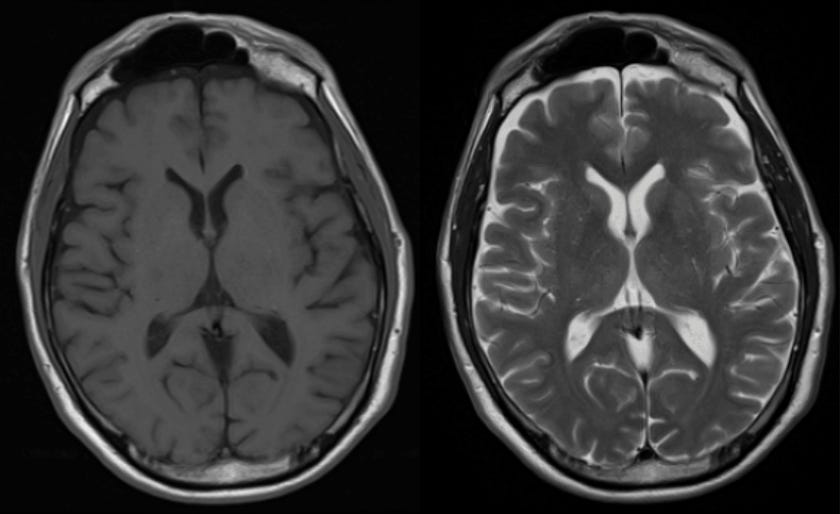
Intuition tells us that since the two contrasts are reflections of the same underlying anatomy, an effective reconstruction method must extract this (and only this) shared structure from the reference scan and infuse it into the reconstruction.
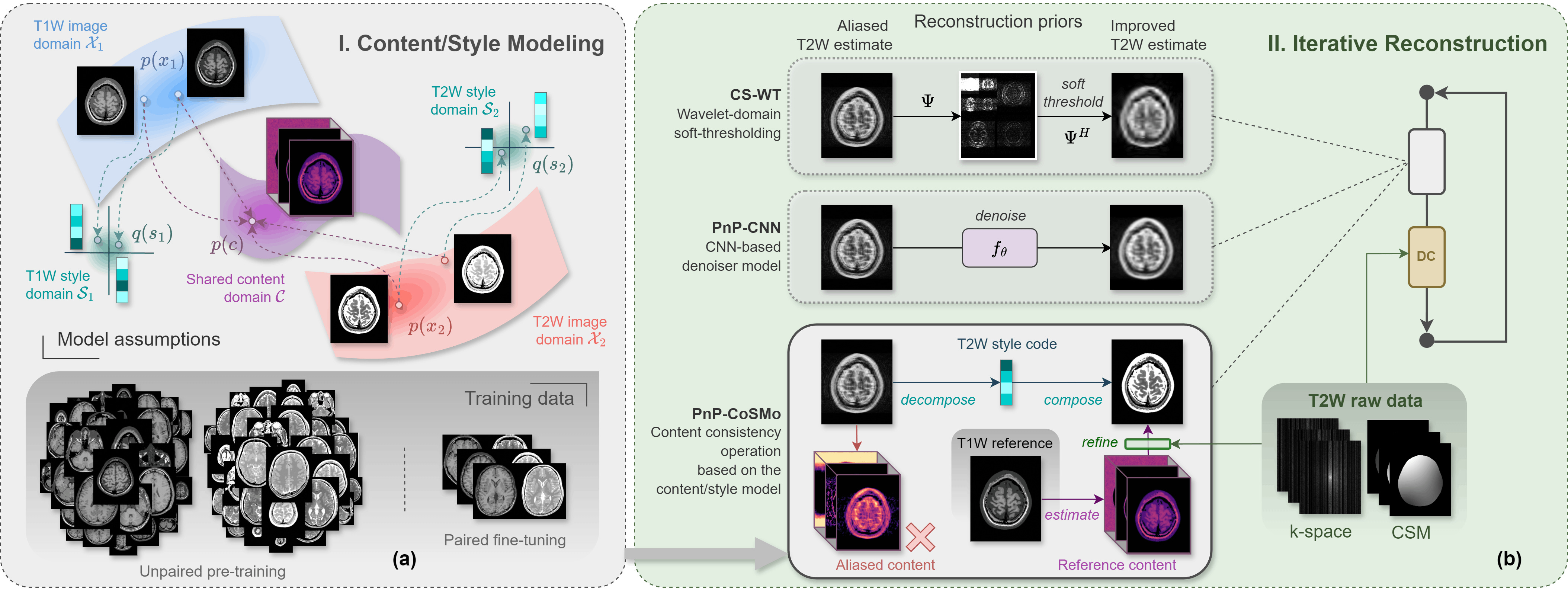
Content/Style Model of a Pair of MR Contrasts
We formalize this intuition by explicitly modeling a pair of MR contrast spaces as emerging from disentangled latent content and style spaces. Content is defined as the shared underlying structure hidden underneath the MR contrasts, and style is the set of contrast-specific latent factors that realize this content into the separate contrasts. We formulate this model using the MUNIT framework[3], which allows learning from purely unpaired image datasets.
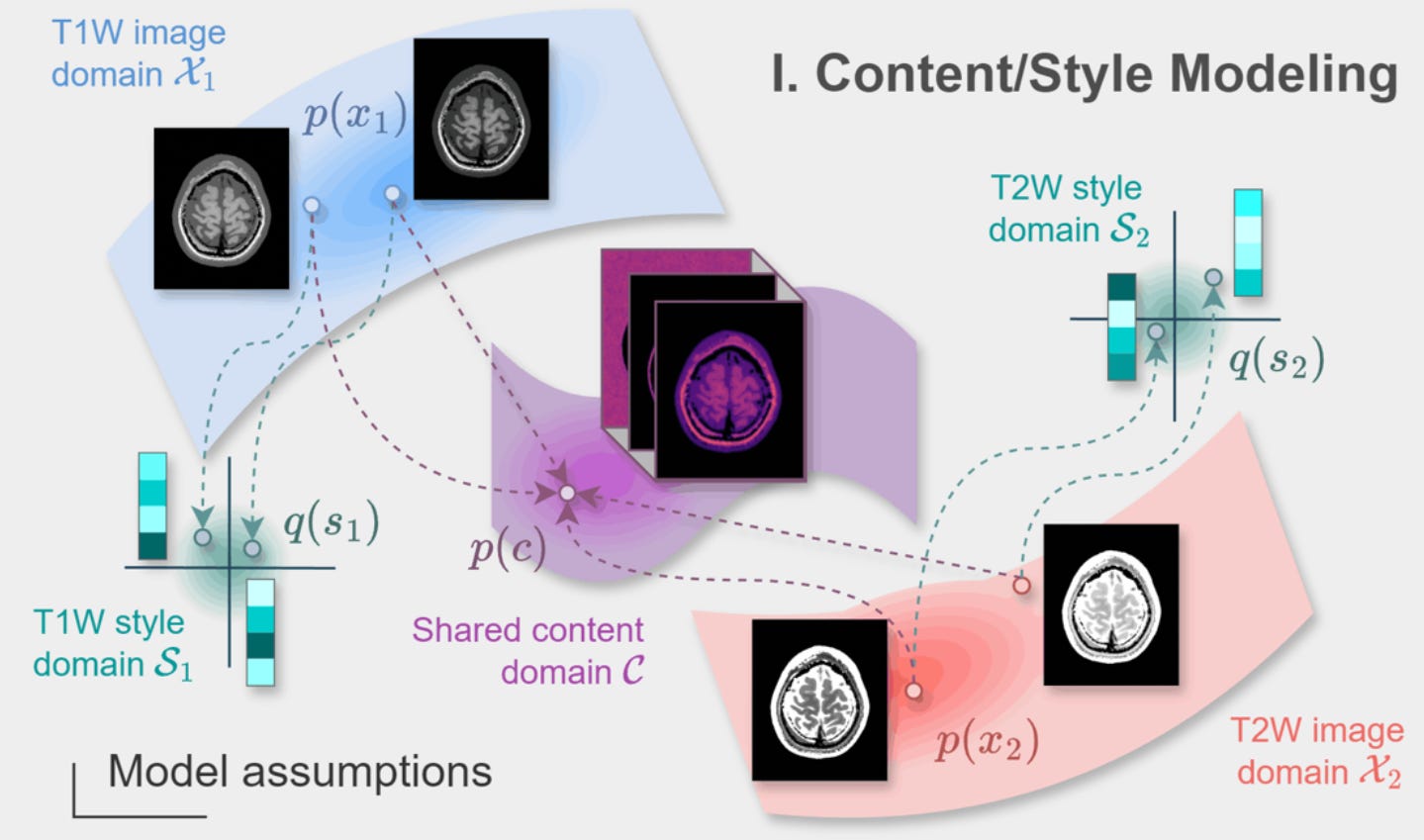
The content/style model M can be specified as the following set of functions
where Gi represents the partially generative decoder mapping the latent disentangled spaces C and Si to the image domain Xi, whereas Eci and Esi are the encoders that jointly represent the inverse of Gi.
The Content-Consistency Operator
With a learned and frozen content/style model in our possession, we then construct a hard content consistency operator around it, which performs a simple yet powerful action: Swap out the aliased content of the reconstruction estimate with clean, high-quality content derived from the reference scan.
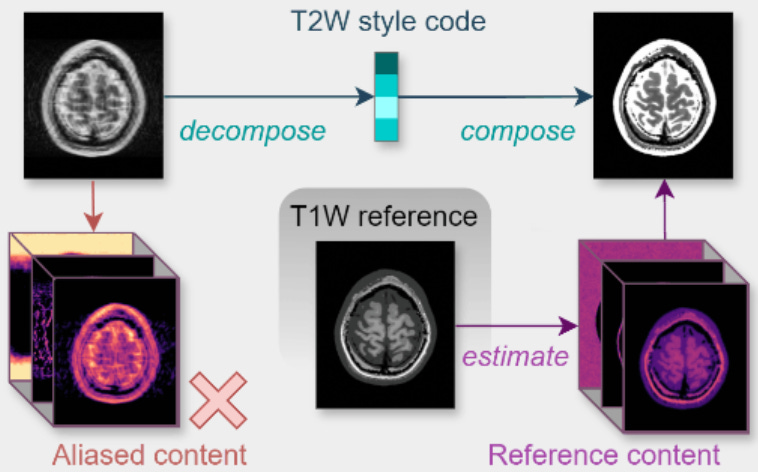
The content consistency operator can be expressed as
where the parameter c is the underlying content, which is estimated from the reference contrast as follows
The outcome is a near-perfect reconstruction obtained in a single step, making it an ideal prior. Plugging this content-consistency operator into the iterative soft-thresholding algorithm (ISTA), thereby replacing its proximal operator and alternating with a data-consistency update, results in an iterative algorithm that converges instantly.
While the underlying content is supplied by the reference contrast, the raw k-space measurements of the target contrast encodes the style information, thus enabling the resolution of the target style s2. Hence, the data consistency update implicitly updates the style towards convergence.
Content Error Correction
At least, this is the case if we assume absolutely no errors in the content estimated from the reference scan, and thus represents an epistemologically impossible upperbound — i.e., an oracle. In practice, this estimated content will not perfectly match the content of the target contrast due to, e.g., inter-scan motion and registration errors, scan-specific artifacts, imperfections in the content/style model, and irreducible modeling errors, to name a few.
This non-zero total error in the estimated content, which we term content discrepancy, must be corrected so that the content-consistency operator can be maximally effective. Utilizing the measured raw k-space samples of the target contrast, we thus propose a generalized error correction step to minimize this entire class of errors online during the iterative reconstruction process.
This sub-problem is formulated as
for a given style estimate s^2 corresponding to the most recent data-consistent image estimate at iteration k of the iterative algorithm. Note that the composite function AG2(.) is an augmented forward model that jointly maps the latent content and style spaces C x S2 directly to the data space Y of raw k-space measurements. We approximate the solution to the above sub-problem by a single gradient descent step at iteration k with a manually tuned step size
We name this error-correction step the content refinement (CR) procedure.
The PnP-CoSMo Algorithm
Thus, the plug-and-play (PnP) content-consistency operator with the content/style model (CoSMo) at its core serves as the foundation of an iterative scheme, and when supplemented by the content error correction step, we arrive at our PnP-CoSMo algorithm[4].
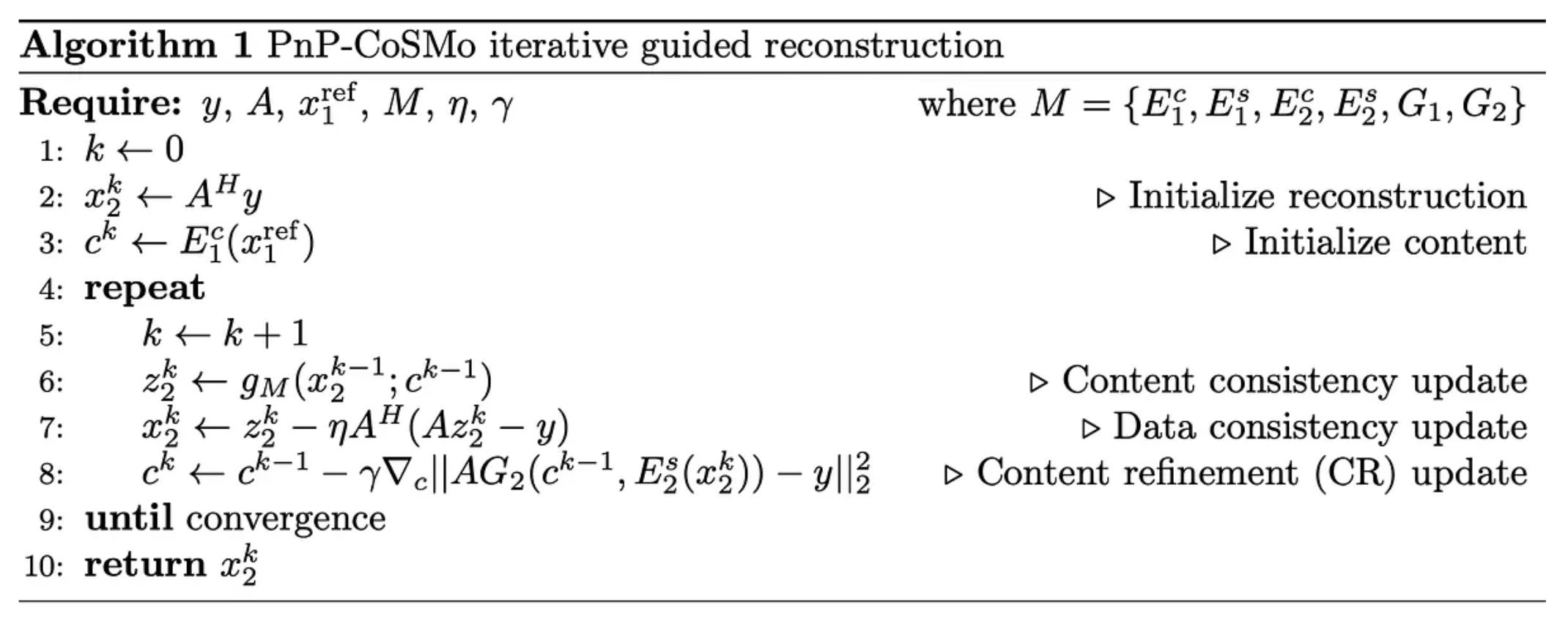
In addition to its conceptual simplicity, PnP-CoSMo offers several unique advantages, which are discussed below.
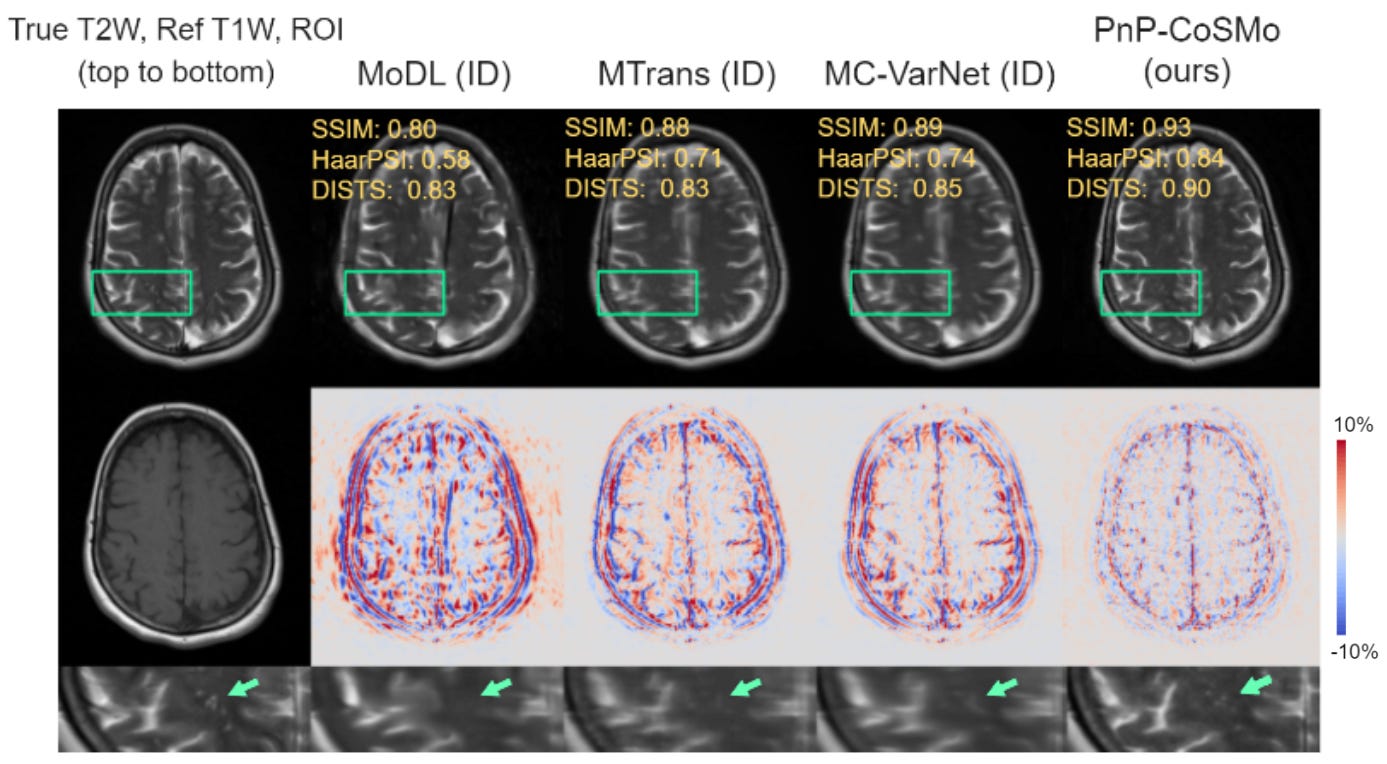
SoTA reconstructions with zero k-space training data
The only learnable component is the content/style model, which can be trained solely on image-domain (DICOM) data — most of which can be unpaired. PnP-CoSMo requires absolutely no k-space training data, unlike end-to-end unrolled networks, which is the currently dominant paradigm of reconstruction models. Following is an example result from our benchmark on the NYU DICOM brain dataset.
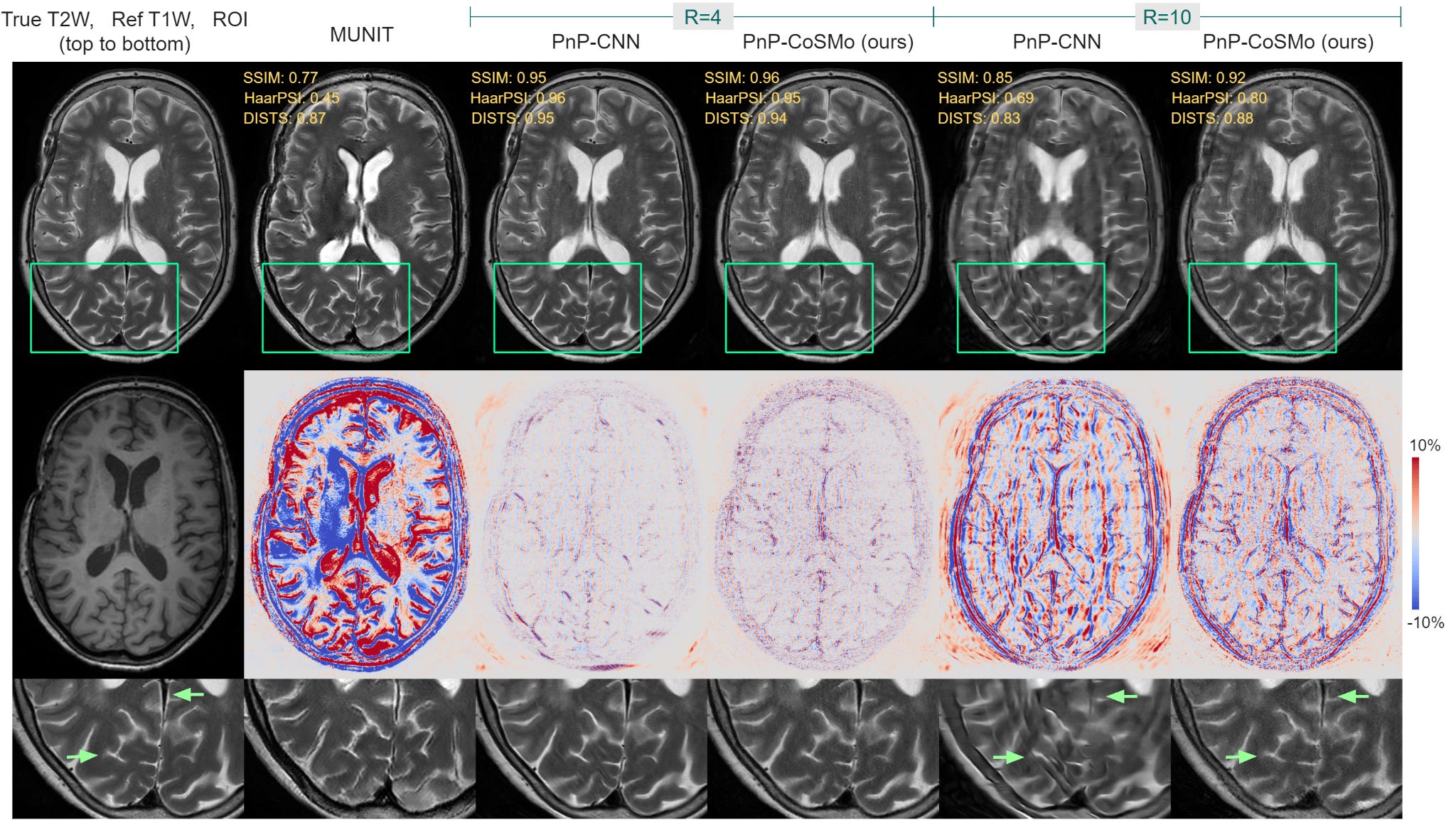
More importantly, a lack of dependence on k-space training data makes PnP-CoSMo applicable in resource-constrained situations. We demonstrated this on our multi-coil raw data from the Leiden University Medical Center (LUMC), where it beats other viable alternatives, as shown below.
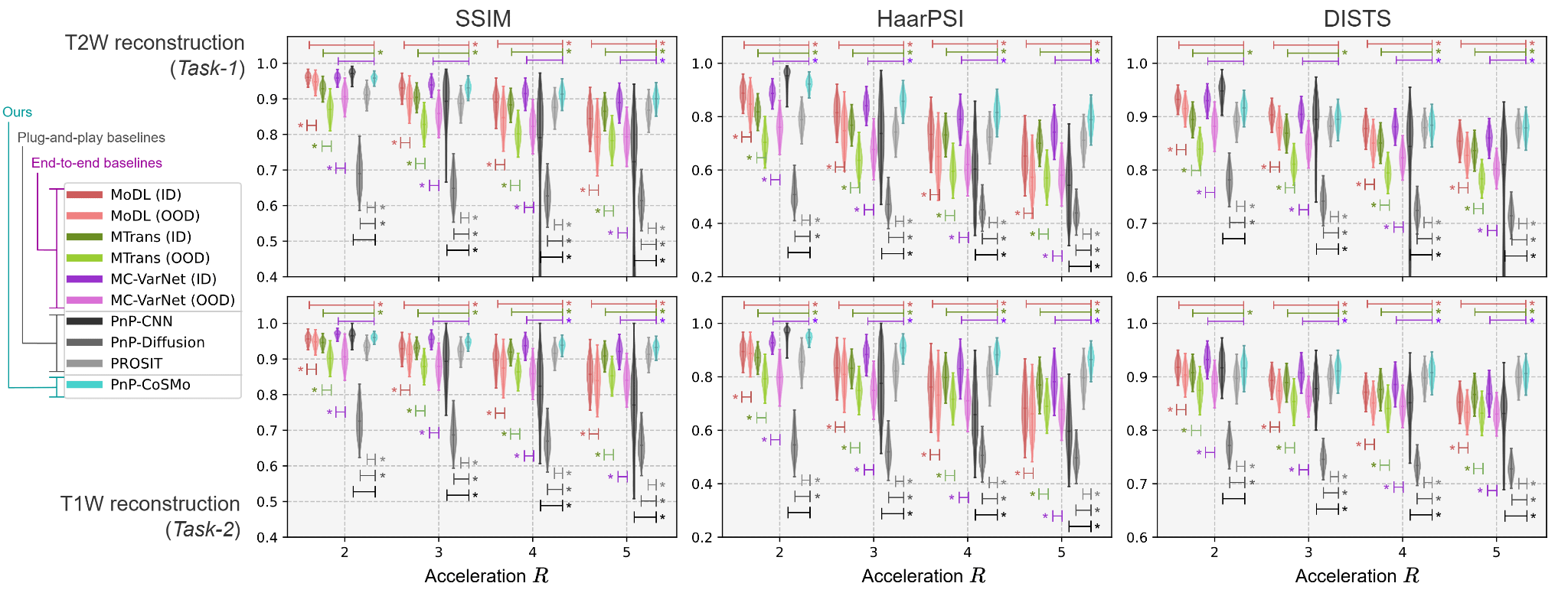
Built-in generalizability across contrasts
In PnP-CoSMo, the learning problem is decoupled from the reconstruction problem, and the content/style model, by design, has no directionality. This model is merely an invertible joint transformation of a multi-contrast image pair. This means that either of the two contrasts can serve as a reference for the other at reconstruction time. We thus overcome a fundamental limitation of unrolled networks, whose performance is tied to the specific contrasts and the problem direction (as well as the acceleration, sampling patterns, etc.) they are trained for.
Built-in explanatory framework
As a consequence of the explicit content and style representation, we can define a set of tangible quantities that provide insight into our system. First, the content discrepancy, as discussed earlier, quantifies a meaningful inconsistency between the expected content and the measured k-space. Second, the optimal content capacity is defined as the optimal spatial size of the content maps for the given multi-contrast image dataset, and represents the amount of shared underlying structure that can be learned from the dataset and utilized in the reconstruction.
Conclusion
At the core of PnP-CoSMo are the content consistency operator and the content refinement procedure. The content consistency operator provides powerful regularization directly at the semantic level of the underlying contrast-invariant content, whereas content refinement provides generalized error-correction of this content to maximize the effectiveness of the operator.
In addition to delivering state-of-the-art reconstructions, the conceptual framework behind PnP-CoSMo offers a langauge to represent multi-contrast MRI. We conjecture that this multi-contrast representation is a more general-purpose abstraction that can serve as a powerful model in applications beyond the guided reconstruction problem considered in this work.
Read the full MedIA article[4] here. The open-source code is available on GitHub.
References
Lustig et al. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magnetic Resonance in Medicine 58, 2007.
Ehrhardt and Betcke. Multicontrast MRI reconstruction with structure-guided total variation. SIAM J. Imaging Sci. 9, 2016.
Huang et al. Multimodal Unsupervised Image-to-Image Translation. ECCV, 2018.
Rao et al. A Plug-and-Play Method for Guided Multi-contrast MRI Reconstruction based on Content/Style Modeling. Medical Image Analysis 113, 2026.
Aggarwal et al. MoDL: Model-based Deep Learning Architecture for Inverse Problems. IEEE Transactions on Medical Imaging 38, 2018.
Feng et al. Multimodal Transformer for Accelerated MR Imaging. IEEE Transactions on Medical Imaging 2022.
Lei et al. Decomposition-based Variational Network for Multi-Contrast MRI Super-Resolution and Reconstruction. ICCV, 2023.
Ahmad et al. Plug-and-Play Methods for Magnetic Resonance Imaging using Denoisers for Image Recovery. IEEE Signal Processing Magazine 37, 2020.
Levac et al. MRI Reconstruction with Side Information using Diffusion Models. Asilomar Conference on Signals, Systems, and Computers, 2023.
Mattern et al. Contrast Prediction-based Regularization for Iterative Reconstructions (PROSIT). ISMRM 2020.